戞俉夞丂F暘晍丒暘嶶暘愅偦偺侾丂堦尦攝抲偺暘嶶暘愅
俁丏倲専掕偺尷奅偲暘嶶暘愅偺摫擖
倲専掕偱偼俀偮偺昗杮偵偮偄偰丆偦偺曣暯嬒偑堎側傞偺偐傪専掕偟傑偟偨丏偙傟傪奼挘偟偰丆俁偮埲忋偺昗杮偵偮偄偰偦偺曣暯嬒偑堎側傞偺偐傪専掕偡傞偙偲傪峫偊偰傒傑偟傚偆丏
椺丗儎僊偺惉挿偑傛偔側傞偲偄偆栻俙丆俛丆俠丆俢傪懳徠嬫偲偲傕偵挷嵏偟偨丏栻嵻張棟偼岠壥偑偁傞偺偐傪抦傝偨偄丏
忋偺椺偱偼丆俢亜俙亜懳徠嬫亜俠亜俛偺弴偱栻偺岠壥偑擣傔傜傟偰偄傞傛偆偱偡丏偝偰丆俙傛傝傕俢偑岠壥偑偁傞偲偄偊傞偐傪倲専掕偱専掕偟丆偝傜偵懳徠嬫傛傝傕俙偑岠壥偑偁傞偲偄偊傞偐傪倲専掕偟丆偙傟傪壗夞傕孞傝曉偟偰傛偄偺偱偟傚偆偐丏
倲専掕偼偁傞摿掕偺俀偮偺昗杮偵偮偄偰偁傞桳堄悈弨乮椺偊偽俆亾乯偱丆偦偺曣暯嬒偵桳堄側嵎偑偁傞偺偐傪専掕偟傑偡丏偟偐偟丆偦傟傪孞傝曉偡偲僨乕僞慡懱偱偼俆亾埲忋偺妋棪偱岆偭偨寢榑傪壓偡壜擻惈偑偁傝傑偡丏
師偺椺傪尒偰傒傑偟傚偆丏偙傟偼1000塇偺偆偢傜偺懱廳偺僨乕僞乮暯嬒丆暘嶶偑摨偠摨堦偺曣廤抍偺傕偺乯偐傜儔儞僟儉偵10塇傪慖傃丆偙傟傪20夞孞傝曉偟偨傕偺偱偡丏摨堦偺曣廤抍偐傜偱傕20夞傕孞傝曉偟偰僨乕僞傪庢傞偲丆傕偭偲傕戝偒偄抣偲彫偝偄抣偺昗杮偺娫偱偼桳堄嵎偑専弌偝傟偰偟傑偆偙偲傕偁傝傑偡丏偡側傢偪儎僊偺栻偺椺偱傕20埲忋偺栻傪摨帪偵幚尡偟偨傜丆栻偺岠壥偑側偔偰傕倲専掕偱偼岠壥偑偁傞偲偄偆寢壥偑弌偰偟傑偆婋尟偑偁傝傑偡丏
僂僘儔偺椺偱偼摨偠曣廤抍偐傜偱傕壗夞傕昗杮傪庢傝弌偣偽丆偦偺椉嬌抂偺娫偵倲専掕偱桳堄側嵎傪専弌偡傞偙偲傪帵偟偰偄傑偡丏偟偨偑偭偰丆偙偺僂僘儔偵偮偄偰壗庬椶傕偺栻昳偵偮偄偰懱廳偵曄壔偑偁傞偺偐傪幚尡偡傟偽丆偨偲偊慡偔偳偺栻昳偵傕岠壥偑側偔丆曣廤抍偵曄壔偑側偔偰傕丆椉嬌抂傪慖傇偲嵎偑偁傞偲敾抐偟偰偟傑偄傑偡丏
偙偺栤戣傪夝寛偡傞庤朄偑暘嶶暘愅偱偡丏柤慜偼暘嶶暘愅偲暘嶶偺尵梩偑偁傝傑偡偑丆俁偮埲忋偺昗杮偺曣廤抍偺暯嬒偵嵎偑偁傞偐傪専掕偡傞庤抜偱偡丏暯嬒偺嵎傪専掕偡傞偨傔偵暘嶶傪暘愅偡傞偲偼偳偆偄偆帠側偺偱偟傚偆偐丏
係丏暘嶶暘愅偲偼丠
愭傎偳偺僂僘儔偺僨乕僞傪傒傞傛偆偵丆僨乕僞偵偼傕偲傕偲偽傜偮偒乮岆嵎曄摦乯偑偁傝傑偡丏偙偺岆嵎偵傛傞偽傜偮偒傪丆張棟偵傛偭偰曄壔偟偨抣偲崿摨偟偰偟傑偆偙偲偵栤戣偑偁傝傑偡丏暘嶶暘愅偲偼僨乕僞偺偆偪丆堄枴偺側偄曄摦乮岆嵎曄摦乯偲堄枴偺偁傞曄摦乮張棟偵傛偭偰曄壔偟偨晹暘乯偵暘偗傞偙偲偵傛偭偰丆張棟偵傛傞曄摦偑岆嵎偵斾傋偰廫暘偵戝偒偗傟偽張棟偵傛傞曄摦偑偁傞偲敾掕偡傞曽朄偱偡丏
俀丏慜夞偺廻戣俁丏偱挷傋偨僨乕僞偵偮偄偰暘嶶暘愅偣傛丏
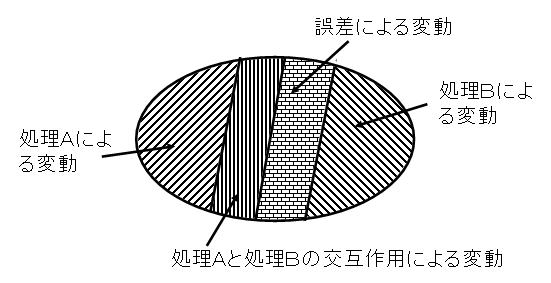
俁丏師夞偺庼嬈偱偼擇尦攝抲偺暘嶶暘愅偵偮偄偰妛傇丏俀偮偺張棟傪慻傒崌傢偣偨偲偒偺僨乕僞偺夝愅曽朄偱偁傞丏
俙丏嶻抧偲昳庬偺堘偄偑儕儞僑偺摐搙偵媦傏偡塭嬁傪抦傝偨偄丏
俛丏巤旍検偲昳庬偺堘偄偑僀僱偺1曚塶壴悢偵媦傏偡塭嬁傪抦傝偨偄丏
俠丏嶌婜偲昳庬偺堘偄偑僩儅僩偺巁搙偵媦傏偡塭嬁傪抦傝偨偄丏
丂擇尦攝抲偱暘嶶暘愅偱偒偦偆側僨乕僞傪尋媶幒偺懖嬈幚尡側偳偐傜庤偵擖傟傞丏偁傞偄偼帺暘偱幚尡偟偰傕偐傑傢側偄丏僨乕僞偵偼斀暅偑俀偮埲忋偁傞偙偲丏僨乕僞偺攝抲偼壓偺恾偺傛偆偵側傞丏
嶻抧偲昳庬偺堘偄偑儕儞僑偺摐搙偵媦傏偡塭嬁傪奺張棟俁偮偢偮偺儕儞僑偱挷嵏偟偨丏
嶻抧丂惵怷丆挿栰丆嶳宍
昳庬丂峠嬍丆傆偠丆傓偮
|
惵怷 |
挿栰 |
嶳宍 |
| 峠嬍 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
| 傆偠 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
| 傓偮 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
乮丂乯乮丂乯乮丂乯 |
廻戣
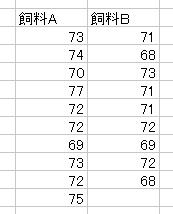
侾丏戞俆夞偺廻戣偱挷嵏偟偨僨乕僞傪梡偄偰丆棏偺廳偝偺偽傜偮偒偑俀偮揦偺娫偱摨偠偱偁傞偐傪桳堄悈弨俆亾偱俥専掕乮椉懁専掕乯偣傛丏
偦傟埲奜偵傕師偺傛偆側椺偑峫偊傜傟傑偡丏
僐儞價僯曎摉偺攧傟峴偒丂梛擔丆揤婥偺俀偮偺梫場
僀僱偺1曚塶壴悢丂昳庬丆巤旍偺俀偮偺梫場
彫捁偺偝偊偢傞夞悢丂婥壏丆懢梲偺柧傞偝偺俀偮偺梫場
俹抣偑0.25側偺偱丆婣柍壖愢偼婞媝偱偒傑偣傫丏
偟偨偑偭偰丆俆亾偺桳堄悈弨偱偼帞椏偺偽傜偮偒偵嵎偑偁傞偲偼偄偊側偄偲寢榑偱偒傑偡丏
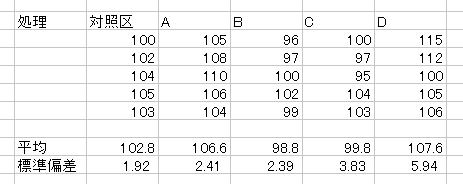
椺丗俙丆俛俀庬椶偺帞椏傪梌偊偰堦掕婜娫帞堢偟偨僴儉僗僞乕偺懱廳偺憹壛検傪應掕偟偨寢壥丆師偺傛偆側寢壥傪摼偨丏帞椏偵傛傞懱廳憹壛検偺偽傜偮偒偵嵎偑偁傞偺偐傪専掕偣傛丏
俥暘晍傪棙梡偟偰俀偮偺昗杮偺暘嶶斾傪嬫娫悇掕偡傞偙偲傕偱偒傑偡偑丆庼嬈偱偼徣棯偟傑偟偨丏
俥暘晍傪棙梡偟偨俀偮偺昗杮偺暘嶶偵嵎偑偁傞偺偐傪専掕偱偒傑偡丏偙偺庤朄偼偙傟偐傜妛傇暘嶶暘愅偺婎慴偲側傝傑偡丏
俀丏俥専掕
俥暘晍偼惓婯暘晍偡傞曣廤抍偐傜柍嶌堊拪弌偝傟偨俀偮偺昗杮偺暘嶶偺斾偵娭偡傞暘晍傪帵偟傑偡丏俀偮偺昗杮偦傟偧傟偺帺桼搙偐傜俥暘晍偑寛傑傝傑偡丏師夞偺庼嬈偐傜妛傇暘嶶暘愅偱偼俥暘晍傪棙梡偡傞偺偱丆戝愗側暘晍偱偡丏側偐側偐堄枴傪偲傜偊偵偔偄暘晍偐傕偟傟傑偣傫丏
侾丏俥暘晍
丂偝偰偳偺傛偆偵偟偰僨乕僞偺曄摦傪岆嵎偲偦傟埲奜偺張棟偵傛傞晹暘偵暘偗傞偺偱偟傚偆偐丠
偦傟偼埲壓偺儁乕僕傪尒偰偔偩偝偄丏
丂暘嶶暘愅偼忋偺儁乕僕偱愢柧偟偨傛偆偵僨乕僞偺曄摦傪夝愅偡傞偺偱偡偑丆幚嵺偵偦傫側偙偲傪寁嶼偟偰偄偨傜戝曄偱偡丏愄偼傕偆彮偟僗儅乕僩側寁嶼曽朄偱偼偁傝側偑傜傕戝曄柺搢側寁嶼傪偟偰偄傑偟偨丏偲偔偵帺桼搙偼傢偐傝偵偔偄奣擮偱偟偨丏偟偐偟丆崱偼僷僜僐儞偱傗傟偽丆傕偲傕偲偺僨乕僞傪擖椡偟偰傗傞偩偗偱暘嶶暘愅偱偒傑偡丏偙偙偱偼僄僋僙儖偺暘愅僣乕儖偵傛傞暘嶶暘愅偺巇曽傪徯夘偟傑偡丏
俆丏暘嶶暘愅偺拲堄揰
俆丏丂僼傿僢僔儍乕偺俁尨懃傪枮偨偟偨幚尡寁夋偺傕偲偱丆暘嶶暘愅傪峴偄傑偡
丂岆嵎偵宯摑岆嵎偑擖傞偲夝愅寢壥偺懨摉惈偑幐傢傟傞婋尟惈偑偁傝傑偡丏宯摑岆嵎傪彍嫀偟偨傝丆暘嶶暘愅偺夝愅偺朩奞偲側傜側偄嬼慠岆嵎偵揮壔偡傞偺偑僼傿僢僔儍乕偺俁尨懃偵弎傋傜傟偨斀暅丆柍嶌堊壔丆嬊強娗棟偱偡丏徻嵶偼屻偺庼嬈偱妛傇梊掕偱偡丏
侾丏丂側傞傋偔斀暅悢偼偦傠偊傑偡
丂崱夞妛傫偩堦尦攝抲偺暘嶶暘愅偱偼斀暅悢偑屄乆偺張棟嬫偱堎側偭偰偄偰傕偦傟傎偳栤戣偼偁傝傑偣傫丏偟偐偟丆棃廡埲崀偵妛傇傛傝暋嶨側暘嶶暘愅偱偼丆斀暅悢偑堎側傞偲夝愅偑柺搢偵側傞偩偗偱側偔丆惛搙傕戝偒偔棊偪偰偟傑偄傑偡丏幚尡奐巒偺偲偒偼斀暅悢傪偦傠偊偰幚尡偡傞偺偑晛捠偱偡偑丆帠屘傗晄拲堄側偳偱斀暅悢偑偦傠傢側偔側傞偙偲傕偁傞偐傕偟傟傑偣傫丏偟偐偟丆偱偒傞偩偗斀暅偺偦傠偆傛偆偵幚尡偡傞偙偲偑婎杮偱偡丏側偍斀暅偑偦傠傢側偄偐傜偲偄偭偰丆堦晹偺僨乕僞傪嶍彍偡傞偺偼娫堘偭偨傗傝曽偱偡丏
俀丏丂暋嶨側幚尡偼側傞傋偔旔偗傑偡
丂慜崁偲傕娭楢偟傑偡偑丆暘嶶暘愅偱偼僨乕僞偑暋嶨偵側傞傎偳丆夝愅偑柺搢偐偮娫堘偊傗偡偔側傝傑偡丏摿偵僐儞僺儏乕僞乕偱寁嶼偝偣傞偲偒偼丆僨乕僞偺擖椡偺巇曽傪娫堘偄傗偡偔側傝丆帺暘偺栚揑偲偡傞暘嶶暘愅傪偡傞偵偼僨乕僞偺峔憿偑暋嶨乮偁傞偄偼偱偨傜傔乯偱丆夝愅晄擻偲偄偆偙偲傕偁傞偐傕偟傟傑偣傫丏偦偺偆偊丆斀暅偑偦傠傢側偐偭偨偲偒偺塭嬁傕戝偒偔側傝傑偡丏昁梫偺側偄暋嶨側幚尡偼旔偗傞偺偼傕偪傠傫偺偙偲丆昁梫偩偲偟偰傕偱偒傞偩偗娙扨側幚尡寁夋偵側傜側偄偐傪傛偔専摙偟偰偐傜幚尡偡傞傋偒偱偡丏幚尡寁夋傪棫偰偨帪揰偱丆偳偆偄偆暘嶶暘愅傪偡傞偺偐傪寛傔偰偍偔偺偑惓偟偄摑寁夝愅曽朄偱偡丏
俁丏丂惓婯暘晍偡傞僨乕僞偑慜採忦審偱偡
丂暘嶶暘愅偱偼斾妑偡傞曣廤抍偦傟偧傟偑惓婯暘晍偡傞偙偲丆曣暘嶶偑摍偟偄偙偲偑棟榑揑偵偼慜採忦審偵側傝傑偡丏偟偐偟丆暘嶶暘愅偼懡彮偦偺慜採忦審偐傜偼偢傟偰偄偰傕丆寢壥偑戝偒偔嵍塃偝傟側偄婃寬惈傪傕偭偰偄傑偡丏
係丏丂偡傋偰偺悈弨偵懳偟偰曣暘嶶偑摍偟偄偙偲傕慜採忦審偱偡
丂悈弨偛偲偺斀暅悢偑傒側摨偠偱偁傞応崌丆偙偺慜採偑懡彮曵傟偰傕塭嬁偼偁傑傝偁傝傑偣傫丏