- 関数の作成
- 戻り値
- 次のプログラムは5桁の乱数を発生させてその約数を全て表示するものです.約数を表示させる for 文を関数にしてみましょう.
これまで print() や sorted(),int() などカッコ内に引数を指定する関数を使用してきました.それらは組み込み関数と言い,あらかじめ用意されているものですが,関数は自分で作ることもできます.同じような処理を違う場所で何度か使用する場合や,ある処理はソースとは別のところに置いておいて,必要な時に呼び出して使用することで全体をすっきりさせたい場合などに使用します.また,今後使用する予定のスレッドなど複数の処理を並列的に実行したいときにも使用されます.
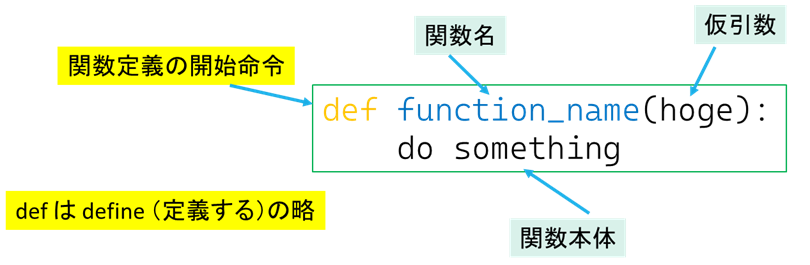
関数を自分で作る場合の基本的な形は以下のようになります.
今,3桁の素数をすべて探すプログラムを考えます.素数とは1と自分自身以外に約数を持たない数ですので,約数があるかどうかで判別する以下のようなプログラムで探索できます.
for i in range(100, 1000):
for j in range(2, i):
if i % j == 0:
break
else:
print(i, end = ' ')
else:
print()
|
実行すると以下のような結果となります.
| 101 103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223 227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349 353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479 487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619 631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769 773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929 937 941 947 953 967 971 977 983 991 997 |
この内側の for 文の処理を関数にしてみましょう.
def find_div(num):
for i in range(2, num):
if num % i == 0:
break
else:
print(num, end = ' ')
for i in range(100, 1000):
find_div(i)
else:
print()
|
関数の構造は以下の図のようになります.

Python では関数はそれが呼び出される前に定義されている必要があります.そして,呼び出しの際に与えられる実引数(上の図では i)と関数定義の def 構文で与えられる仮引数(上の図では num)の名前は違っていても構いません.
今回のこの関数の仕事は画面に数字を表示するだけのものでした.print() のようなものです.
関数では何らかの処理を行った後,結果としての値を呼び出したところに返すこともできます.返す値のことを戻り値と言います.順列と組み合わせで学習した組み合わせを計算するために階乗計算を行う関数を作ってみましょう.
from random import randint
def fact(n):
f = 1
for i in range(2, n + 1):
f *= i
return f
m = randint(5, 10)
n = randint(2, 4)
#m = 5
#n = 2
#5C2 = 10
factorial = fact(m) // fact(m - n) // fact(n)
print(f'Combination {m}C{n}: {factorial}')
|
| Combination 7C4: 35 |
# を使ってコメントアウトしているのは自分で計算結果が合っているかを確認するためです.階乗の計算は例えば 5C2 であれば次のように行いますので,m = 5 で n = 2 のとき 10 になれば合っていることになります.

演習
from random import randint
num = randint(10000, 99999)
print(f'Divisors of {num}: ', end = '')
for i in range(1, num + 1):
if num % i == 0:
print(i, end = ' ')
else:
print()
|
Divisors of 17653: 1 127 139 17653 |
- ファイル処理とは
- CSVとは
- 書き込み
- ファイルの読み出し
- 2重の for 文(内包表記)を使用して上の読み込み結果を int 関数を用いて数値化して見ましょう.
- 平均値
プログラムを実行して得られた値をPCに保存することや,PCに保存されている値を使ってプログラム内で処理を実行することはよく行われます.そのために自分が作ったプログラムがPC内部にアクセスしてファイルを書き込んだり読み出したりすることをファイル処理をいいます.今回はCSV形式のファイルのやり取りを学習します.
CSV とは Comma Separated Value の略です.カンマ(コンマ)で区切られたデータ群という意味ですが,区切り記号はカンマ以外にもスペースやTABなどさまざまなものが利用可能です.また,個々のデータを二重引用符 " でくくる形式とそうでない形式があります.
今回使用するのはカンマ区切りのデータで引用符でくくらない形式とします.
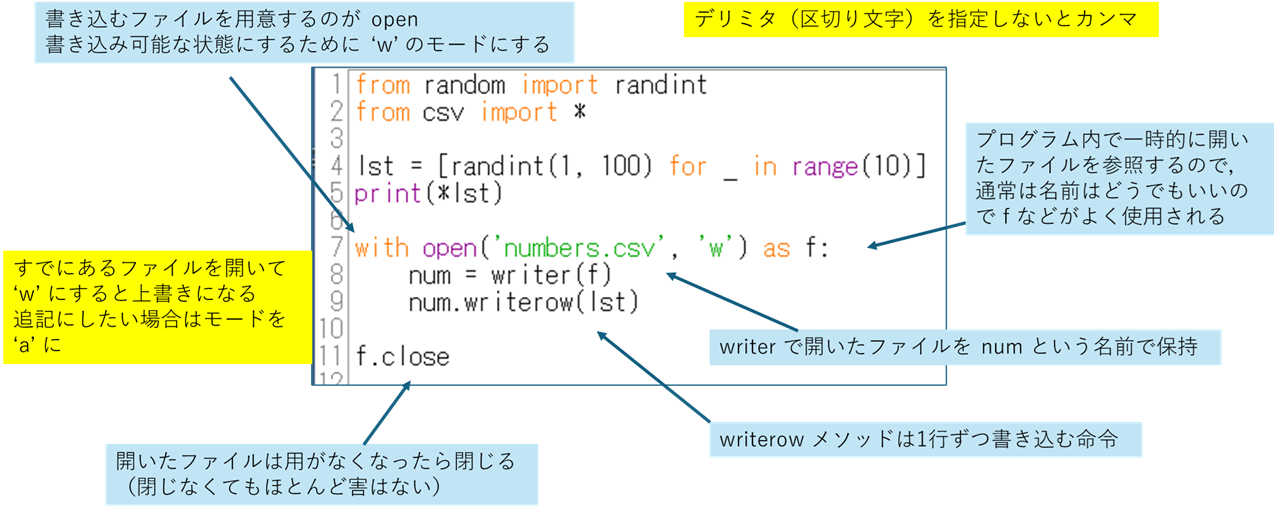
Python に標準で備わっている csv モジュールを読み込むことで CSV ファイルを扱う各種の関数やメソッドを利用できるようになります.試しに乱数データを生成して書き込んでみましょう.
from random import randint
from csv import *
lst = [randint(1, 100) for _ in range(10)]
print(*lst)
with open('numbers.csv', 'w') as f:
num = writer(f)
num.writerow(lst)
f.close
|
実行すると画面には以下のように乱数が表示されます.
99 50 85 90 3 23 80 9 82 16 |
そして,プログラムが保存されているフォルダには numbers.csv というファイルが出来ているはずですので,開いてみましょう.

このCSVファイルを開いたままもう一度プログラムを実行しようとすると以下のようにエラーが出ます.
Traceback (most recent call last): File "D:/Backup_20241015_onedrive/class/2025/elec_energy/20251217/num_write.py", line 7, inファイルが開いたままの状態なので書き込みができないというエラーです.同じ名前で保存しようとしていますので,そのようにエラーになります.with open('numbers.csv', 'w') as f: PermissionError: [Errno 13] Permission denied: 'numbers.csv'
この writer 関数の動作は以下のように考えてください.
先ほど作成した numbers.csv をいったん閉じて,今度はそのデータを読み出すことを行ってみましょう.ついでに平均値も求めています.
from statistics import *
from csv import *
with open('numbers.csv', 'r') as f:
num = reader(f)
txt_data = [txt for txt in num]
f.close
print(txt_data)
num_lst = [int(txt_data[0][i]) for i in range(0, 10)]
print(*num_lst)
print(f'Mean of above numbers: {mean(num_lst)}')
|
実行すると結果は以下のようになります.
[['99', '50', '85', '90', '3', '23', '80', '9', '82', '16'], []] 99 50 85 90 3 23 80 9 82 16 Mean of above numbers: 53.7 |
読み込んだデータは実はややこしい形式になっているので,元の数値に戻すためにはいろいろと手順があります.以下の図を参考に理解してください.

2次元データの作成と書き込みは以下のように行います.ここでは10行3列の乱数データを作って書き込みます.
from random import randint
from csv import *
lst = [[randint(1, 100) for _ in range(3)] for _ in range(10)]
print(lst)
with open('data_array.csv', 'w', newline = '') as f:
data = writer(f)
data.writerows(lst)
f.close
|
注意することは open でファイルを開くときに引数の中に newline = '' を書いておくことです.これが無いと1行ごとに空行が入ってしまいます.また,データの書き込みも複数行なので writerows メソッドになっています.
上で作成したデータを読み込むには以下のようにします.
from csv import *
with open('data_array.csv', 'r') as f:
data = reader(f)
txt_data = [txt for txt in data]
f.close
print(txt_data)
|
| [['85', '11', '60'], ['63', '96', '77'], ['20', '67', '49'], ['19', '4', '86'], ['47', '93', '66'], ['26', '94', '41'], ['40', '99', '99'], ['76', '68', '65'], ['99', '88', '68'], ['8', '5', '36']] |
演習問題
[['85', '11', '60'], ['63', '96', '77'], ['20', '67', '49'], ['19', '4', '86'], ['47', '93', '66'], ['26', '94', '41'], ['40', '99', '99'], ['76', '68', '65'], ['99', '88', '68'], ['8', '5', '36']] |
手順: txt_data のリストを作るところまでは同じ 内包表記ではインデックス変数の i と j の順番に注意して int(txt_data[i][j]) により整数化 |
先ほどのプログラムに各行の平均値を計算して以下のように表示するように変更しましょう.
85 11 60 : 52.00 63 96 77 : 78.67 20 67 49 : 45.33 19 4 86 : 36.33 47 93 66 : 68.67 26 94 41 : 53.67 40 99 99 : 79.33 76 68 65 : 69.67 99 88 68 : 85.00 8 5 36 : 16.33 |