第14回 実験計画と統計解析の実際
1.重回帰分析
単回帰分析では一つの説明変数(独立変数)で目的変数(従属変数)を説明しようとしました。しかし、現実にはいくつかの要因が関与して、ある一つの現象が決まるものはたくさんあります。例えば、水稲の収量は環境要因だけでも、気温、降水量、日射量、風速、湿度などが関与していると考えられます。これらの要因のうち、ある要因はかなり強く収量を支配し、ある要因はそれほど強くは支配していないかもしれません。このように目的変数を説明する説明変数を複数取り上げたいときには重回帰分析を行うことができます。
重回帰分析は単回帰分析を拡張したものなので、単回帰分析と同じように目的変数は正規分布し、しかもその誤差は説明変数に依存しないことが前提条件となります。さらに説明変数自身は指定できる値であり、誤差を持たないことも前提条件となります。
重回帰分析の計算はコンピューターでします。エクセルでも可能です。
3) ブロック因子
実験の精度を高めるために,実験の場の局所管理に用いる因子で,その水準自身は特性値に若干の影響を与えるかもしれませんが,他の(制御・標示)因子とは交互作用を持たないと考えられる因子をブロック因子といいます.
例:水稲の品種試験においては圃場のムラなどです.
4) 層別因子
制御因子や標示因子と交互作用を持つおそれがありますが,実験の場でも適用の場でも制御できない因子を層別因子といいます.
例:水稲の品種試験では,年度,地域などの因子を層別因子と考えることができます.同じ品種でも年によって成績が違うこともありますし,地域によっても成績が異なることも考えられます.しかし,年度や地域は制御できない上に,品種との交互作用が認められることがよくあります.
2.実験を始める前にすること
A.要因(因子)をあげます
実験の目的が例えば,「人の血圧に及ぼす摂取塩分の影響」であっても,摂取塩分と血圧だけを測れば実験は終わりとは行きません.血圧に影響を及ぼす要因は多数ありますから,摂取塩分の影響はそのような要因(とりわけ交互作用のある要因)を無視しては解析できません.
したがって,まず実験目的が決まれば,目的とする結果に影響を及ぼしそうな要因をすべて挙げます.そのような要因を次に,①制御因子,②標示因子,③ブロック因子,④層別因子に分類します.
B.要因間の関係を図示する
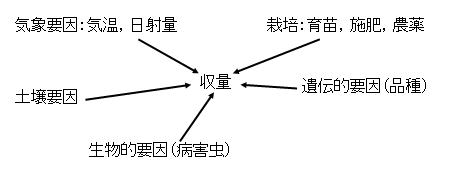
下の図はイネの収量に影響を及ぼす要因とそれぞれの関係を図示したものです.実際の実験では多数の因子のうち,少数のものに絞ってから,実験するが,実験を始める前に要因間の関係を図示しておくことは大切です.
C.要因を分類します
1) 制御因子
その最適条件(水準)を知るために取り上げる因子で,実験の場ではもとより,その結論を適用すべき(生産の)場においても,その条件を制御できる因子を制御因子といいます.
★ 制御因子を決める(複数でもよい)
1)島根県で多収となる品種はどれかを決める 制御因子:品種
2)多収となる品種とそれに適した作期を決める 制御因子:品種,作期
3)多収となる品種とそれに適した作期・施肥量を決める 制御因子:品種,作期,施肥量
2) 標示因子
その最適条件を知ることは直接の目的ではありませんが,この因子の水準が異なると,他の(制御)因子の最適条件が変わるおそれがある(交互作用がある)ために実験に取り上げる因子です.標示因子は実験の場では制御されなければなりませんが,適用の場では必ずしも制御できるとはかぎりません.
1)島根県で多収となる品種はどれかを決める 制御因子:品種
この場合,作期や施肥方法が標示因子となるかもしれません.
作期は水の得られる時期(梅雨など),水稲以外の作物(野菜,果樹,チャなど)の忙しい時期などによって,左右され,かならずしも現場の農家では制御できません.施肥方法でも,琵琶湖など湖沼,河川の近くのために水質保全の理由から,多収になる施肥方法が認められないこともあるでしょう.
このように制御因子に交互作用のある標示因子が何かは専門的知識だけでなく,現場への理解も必要となることもあります.
D.実験を計画します
次に実験を計画します.フィッシャーの3原則(反復・無作為化・局所管理)を満たすような乱塊法の実験計画が望ましいでしょう.実験計画が決まれば,どのような分散分析をするかが決まります.空欄の分散分析表をあらかじめ作っておくのもよいでしょう.
ふつうは要因を複数同時に取り扱う要因実験の方が利点が多いです.複数の要因を同時に実験すると,A.実験の精度自体を高めること,B.交互作用を見積もれること,C.実験のデータのばらつきをいろいろな角度から評価できる分散分析ができることなど有利な点が多いです..
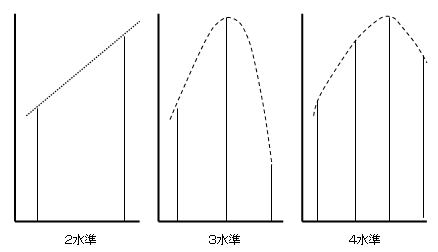
取り上げるべき実験の因子が決まれば,それぞれの因子についていくつ水準を取るかを決めます.質的因子のときは利用できるあるいは考慮すべき数で決まります.質的因子とは例えば品種です.量的因子の場合,回帰分析します.直線を仮定するときは3つ程度,2次曲線や対数,指数曲線を仮定するときは4つ程度の水準が必要です.水準はできるだけ広い範囲をカバーする方がよいです.特に最初のうちから限られた範囲の水準でしか実験ませんと,最適な値や新発見を逃すことになるかもしれません.実験による情報が増えれば,水準の幅を狭めていくことも可能です.
E.どのような統計解析をするかを決めます
データを取り終わってからどういう解析をするかを決めるのは本当は正しくありません.
2つの母集団の平均値の有意差検定 t検定
3つ以上の母集団の平均値の有意差検定 分散分析
分散分析の後,質的因子の場合は多重検定,量的因子の場合は回帰分析を行い,最適な水準がどれかを決めることができます.
C. 母平均を95%信頼区間などをつけて推定します
自分の得たデータを平均だけみて判断するのは好ましくありません.どの程度データの平均が信頼できるかの指標である標準誤差を計算しておきます.
3.データを集めたら
1.基礎統計量を計算する
A. データの数が多いとき
データが30以上あれば,度数分布,ヒストグラムを書いてデータの分布を調べることもできます.次に平均,分散,標準偏差などを計算します.データが正規分布から大きく外れると判断したら,メジアン,モードなども有用な統計量です.
B. 異常値をチェックする
データの中に異常に大きい値,あるいは小さい値があるときの対処法は以下に述べるような方法があります.a.は必ず行うべきです.b.~d.はどれを用いるべきかは実験の目的,データの性質などを検討して,できる限り実験を開始する前に決めておきましょう.
a.異常値の原因が明らかなとき
異常値の原因を調べ,測定におかしな点があるときは除去します.
b.反復数を増やす
もし可能であれば,実験を繰り返し,データを増やすとそのデータが異常値であるかより明確になり,かつ異常値が平均値に及ぼす影響も軽減されます.
c.異常値の除去
異常値を除去したいときはスミルノフ法(スミルノフ・グラブス法)あるいはディクソンのQテストで検定し,異常値であると認められるときは除去できます.根拠もなく,不都合なデータを捨てるのは好ましくありません.
d.内部平均を用いる方法
集めたデータのうち両極端な値,すなわち最大値と最小値を除いたデータから得た平均を内部平均といいます.内部平均を用いるとデータのばらつきはかなり小さくなることが多いです.データが3つのときの内部平均はメジアンと一致します.
2.データ間の相関を分析します
得られたデータについてはどのデータとどのデータに相関があるかを散布図と相関係数を計算することで調べます.はじめは想定しなかった関係を見つけることもあるでしょうし,最初に考えていたような関係がないこともあるでしょう.データをグラフのように見える形にすることは相関関係を知るだけでなく,異常値やデータのグループ分けを見つける上でも重要なことです.
3.目的に応じた統計解析を行います
実験計画で決めた分散分析をここで行います.