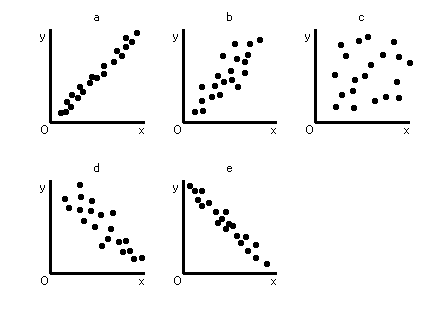��1�P��@���U���͂��̂R�@�����v��@
�i�Q�j�����ɂƂ��Ȃ��덷���ǂ����䂷�邩�H
�@�f�[�^����舵�������ɂ͌덷���K���t�����܂��D���̌덷�������ɐ��䂷�邩�������œ���ꂽ�f�[�^�̐��m���C�M���������߂��ŏd�v�ł��D�덷�͑�ʂ���ƁC�n���덷�Ƌ��R�덷�ɕ������܂��D���̂����n���덷�͕���������덷�ł���C���̌n���덷�������ɏ���������̂����l���Ă݂܂��傤�D
�@�܂��n���덷�Ƃ͂ǂ�Ȃ��̂ł��傤���D
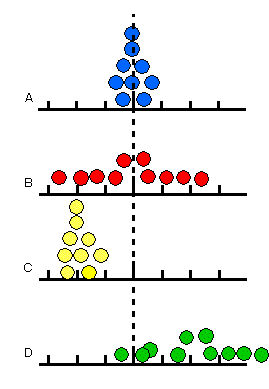
�@�E�̐}�����Ă��������D�`�C�a�C�b�C�c�̂S�l�����鑪������J��Ԃ��܂����D�^�̒l�͓_���Ŏ����Ă���܂��D�`�C�a�͕��ς͐^�̒l�ɋ߂��̂ł����C�a�̓f�[�^�̂�����傫���悤�ł��D����C�b�C�c�͕��ς��^�̒l����O��Ă��܂��D���āC�a�Ƃb�ł͂ǂ���̕��͂��悢�̂ł��傤���D
�@�����C�b�̒l������肾�Ă��Ȃ���C�a�̕������͂͂悢���ƂɂȂ�܂��D�Ȃ��Ȃ�C�a�Ȃ�Ύ����𑝂₹�C�^�̒l�ɕ��ς��߂Â��܂����C�b�͂�������������Ă��^�̒l�ɂ͋߂Â��܂���D�n���덷�Ƃ͂��̂悤�Ȃb�̏o���덷���Ƃ����܂��D������吔�̖@���ł�������f�[�^���W�߂�ΐ^�̒l�ɋ߂Â��Ƃ����Ă��C�n���덷�ł̓f�[�^�𑝂₵�Ă����ς���̌덷���������Ȃ�Ȃ��̂ł��D
�@���Ȃ킿�n���덷������C����ɋC�Â��Ȃ���C���U���͂��ē�����덷�ɂ͌n���덷������Ȃ����ƂɂȂ�C�f�[�^�̉��߂�傫���Ԉ���Ă��܂��܂��D
�@���������āC�덷�S�̂�����������ȑO�ɁC�n���덷�����炷�C�Ȃ����C�����Č��点�Ȃ��ꍇ�ɂ͋��R�덷�ɓ]�����邱�Ƃ��K�v�ɂȂ�܂��D���̕��@�������̂��C�t�B�b�V���[�̎O�����ł��D
�@��̓I�ɂ͌n���덷�͂ǂ̂悤�Ȃ��̂�����ł��傤���D�r�Ŏ�������Ƃ��܂��傤�D10���̓����i��̗Y�̗r���W�߂��Ƃ��Ă��C��C�̏d�C�e�̈�`���̑����낢��ȗv�f�����������E�������ł��D��������Ƃ��Ɍn���덷���o���Ƃ킩���Ă�����̂͂��炩���ߏ�������̂��悢�̂ł����C�̏d�C��Ȃǂ̑S������ȗr��10�����W�߂邱�Ƃ͌����I�ł͂���܂���D���邢�͌n���덷�͏o��̂�����ǁC����ǂ��납�C�n���덷�̌����̒肩�łȂ����̂�����܂��D�ޏ�̒n�̓����C���͋@�B�̓��⎞�Ԃɂ������ȕϓ��Ȃǂ͌n���덷�݂܂����C�������ڂ������ׂ悤�Ƃ���͎̂萔�ł��D
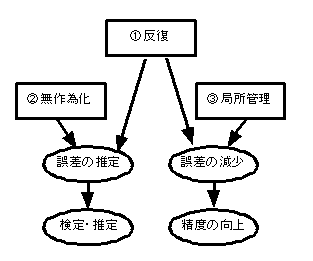
�t�B�b�V���[�̎O�����ł͂��̂悤�Ȍn���덷�𐧌䂷�邽�߂ɂ܂�
�P�D����
�@�덷�����ς��邱�Ƃ��ł��Ȃ��ƁC���䂷��ɂ�����ł��܂���D�덷��m��ɂ͏��Ȃ��Ƃ����������Ŏ������J��Ԃ��K�v������܂��D������Ƃ����܂��D
�@����ɔ����𑝂₷�ƁC���ςɂ��Ă̌덷�ł���W���덷���̂��̂��������Ȃ�܂��D
�@���Ȃ킿�C������݂��邱�Ƃɂ���āC�덷�̕]���ƌ덷�̌����̂Q���������܂��D
�t�B�b�V���[�̎O�����ł͉��̐}�̂悤�ɂR�̌��������ꂼ��덷�̐���ƌ����ɖ𗧂��C�덷�𐄒肷�邱�Ƃŕ��U���͂̂悤�ɓ��v�I����E���肪�o���C�덷���������邱�Ƃɂ���Đ��x�����シ�邱�Ƃ��ł��܂��D
�Q�D�����
�@�n���덷�̂���f�[�^�ɕ��U���͂Ȃǂ̓��v�I��@��K�p���Ă����������ʂ͓����܂���D�n���덷���ł��邾�����R�덷�ɓ]��������@����Ƃ����܂��D�Ⴆ�C�r�͌̂ɂ���ĉa�ɑ��锽�����Ⴄ��������܂���D�^����a���ǂ̗r�ɗ^���邩��ׂɁi�����_���Ɂj���߂邱�Ƃɂ���āC�r�̌̊ԍ��قɊ�Â��n���덷�͖��������܂��D
�Ⴆ�Ηr�̑̏d�ɂ���āC���ʂ��ς��Ƃ��܂��傤�D�������̏d�̗r�R���ɂ`�C�傫���̏d�̗r�R���ɂa�̖��^����Ȃ�C���̌��ʂɂ͌n���덷�����荞�݂܂��D���������n���덷�͐�قǂ̐}�̂b�̌��ʂƓ������C�f�[�^�̌������̂��������������i�Ȃ��Ȃ�C�̏d�̋߂��r�̃f�[�^�͂����������������j����悯���ɉ��߂��ԈႤ���ƂɂȂ肩�˂܂���D�̏d�ɊW�Ȃ��C����ׂɎ�������Ƒ̏d�̂������ɂ��덷�i�n���덷�j�����R�덷�ɓ]������̂ŁC�f�[�^�̌�������̌덷�͑傫���Ȃ�܂��D�������C������������ʁC���R�덷�U���͂Ȃǂŕ]���ł���̂ŁC���ۂɂ͎����̌��o�͍͂��܂�܂��D
�@�Ⴆ�C��ʕ��͂̏ꍇ�ł��`�C�a�C�b�̂R�̃T���v�����R�����肷��Ƃ��ɁC�`�C�`�C�`�C�a�C�a�C�a�C�b�C�b�C�b�̏��ŕ��͂���l���������܂��D�������������͌덷�͏������Ȃ�܂����C���͂̂Ƃ��̎���̊��i���x�C����C���j�̉e���ɂ��n���덷�����R�덷�ɓ]�����Ă��Ȃ�����^�̒l����傫������Ă��܂��댯������܂��D�X��̕��͂�ׂɍs���ׂ��ł��D���̏ꍇ�C��������f�[�^�̌덷�͑傫���Ȃ�܂����C����͎����̂ǂ����Ɍn���덷�̌��������邱�Ƃ������悢�؋��ł���C����Ɏ����̐��x�����߂�@���^����ꂽ�Ƃ������Ƃɂ��Ȃ�܂��D
�R�D�Ǐ��Ǘ�
�@�t�B�b�V���[�̎O�����̍ŏ��͔����ł���悤�ɁC�������Ȃ������͌덷��]�����悤���Ȃ��C�t�B�b�V���[���g�͂��������͎̂����ł͂Ȃ��C�����o���𑝂₵���ɂ����Ȃ��ƃR�����g�����炵�����炢�C�����͍ł��厖�Ȃ̂ł����C�����𑝂₷�ƌ덷��ʂ̈Ӗ��ő��₵�Ă��܂��\��������܂��D��قǖ�����̗�ŋ������悤�ɁC�r�̓����𑝂₷���Ƃ́C�����𑝂₷���ƂȂ̂ł����C�S�������r�����̐��ɂ��Ȃ��ȏ�C�r�̌̂ɂ�鍷�͌덷�������邱�ƂɂȂ�܂��D��ʕ��͂ł����̕��͂����邽�߂ɉ����Ԃ��������邤���ɁC�����̏�̔����ȕϓ��ɂ���āC�덷�����傷��\��������܂��D
�@���̂悤�ɔ����𑝂₷�Ƃ��̌덷�̕ϓ����C�r�ł���Α̏d�̋߂����̂��C���͂ł���Ύ��ԓI�ɋ߂����镔���i�ߑO�Ƃ��ߌ�Ƃ��j�ɁC�����Ŕ�r�������P�g�Ă邱�Ƃɂ���āC�덷�����̕����̈Ⴂ�ɓ]�����āC�������邱�Ƃ��ł��܂��D������Ǐ��Ǘ��Ƃ����C���̂悤�Ȃł��邾���ψ�ɂ��������̏�̈ꕔ���u���b�N�Ƃ����܂��D
�@�����v��@�ł́C�n���덷�����̂悤�ȋǏ��Ǘ��ɂ���āC�u���b�N�Ԃ̍��ɂ��邾���łȂ��C���U���͂ɂ���āC�u���b�N�Ԃ̌덷�i���Ȃ킿�u���b�N�ɂ������ʁC�����ł����덷�j����ʂł��܂��D
�S�D����@�̕��U����
�@����������ꍇ�C�����Ɩ�����͂��Ȃ炸�K�v�ł��D�������Ȃ���Ό덷�����ς��邱�Ƃ��ł��܂���C���U���͂ł��܂���D����������Ȃ���C�f�[�^�̕ϓ��������ɂ����̂Ȃ̂��C�덷�ɂ����̂����킩��܂���D�n���덷�������ϓ����番���ł��Ȃ�����ł��D�t�B�b�V���[�̂R�����̂����C�����Ɩ�����������̂����S������@�Ƃ����܂��D
�T�D���e�����i�@
�U�D�h��
�`�D���̎�����z�u���܂��傤�D�Ȃ��C�z�u�͖���ׂɂ��܂��D
�T�@�R�i��i�`�C�a�C�b�j�̐���̎��ʔ�r���S�u���b�N�̗���@�Ŏ�������D
�U�@����i�R�C�U�C�X�C�P�Q�N�j�ƕޏ�̍���i���C���C��C��j�̂Q�̃u���b�N���q�ɂ���āC�`�̂S�͔̍|���@�i�`�C�a�C�b�C�c�j���r����������s���D
�P�D�����v��@
�@�����v��w�Ŏ�舵�������ɂ͎��̂Q�̓���������܂��D
�i�P�j�@���낢��ȏ�����l�דI�ɐݒ肵�āC���̌��ʂ̔�r��ړI�Ƃ�������ł���
�i�Q�j�@���������̉��Ŏ������J��Ԃ��Ă��C���ʁi�f�[�^�Ŏ������j�͕K���������ł͂Ȃ��C���Ȃ�̂���������D
�i�P�j�ɂ��ẮC�ȉ��łǂ̂悤�ȏ�����ݒ肷�邱�Ƃ��ł���̂��C����ɏ����͂P�����Ƃ͌��炸�C�����̏�����ݒ肷��������K�v�ȏꍇ������C���̂Ƃ��̂��ꂼ��̏����̓������l���܂��D
�i�Q�j�ɂ��Ă͎����ł͐ݒ肷������ȊO���ψ�ɂ��Ȃ炸�ł���킯�ł͂Ȃ��C���̂悤�ȕs�ψꂳ�������Ō덷�������܂��D�����ɂ��Č덷�����������邩�C���邢�͎������ʂɕ�̂Ȃ��悤�Ȍ덷�ɓ]�����邩���ȉ��ŏq�ׂ܂��D
���Ȃ킿�����v��@�̖ړI��
�i�P�j�@�����Ŏ�舵�����q�i�v���j��K�ɑI�����邱��
�i�Q�j�@�����ɂ����̂ł���덷�𐧌䂷�邱��
�ł��D
�Q�D���q�Ɛ���
�@�����ɂ����Ă��̏�������X�ɕς��Ĕ�r������̂����q�Ƃ����C���q�̎�肤������𐅏��Ƃ����܂��D
�Ⴆ�C����͔̍|�����ł́C���q�Ƃ��āC�i���{��ʂȂǂ��l���邱�Ƃ��ł��܂��D
| ���q |
���� |
| �i�� |
�R�V�q�J���C�n�i�G�`�[���C�q�m�q�J�� |
| �{��� |
0, 4, 8, 12g/m2 |
�@���q�͑傫���ȉ��̂S�ɕ��ނł��܂��D
�i�P�j������q�@���̍œK�����i�����j��m�邽�߂Ɏ��グ����q
�i�Q�j�W�����q�@������q�ƌ��ݍ�p�����邽�߂Ɏ��グ����q�̂����C�����̏�ł͐���ł�����q
�i�R�j�u���b�N���q�@�Ǐ��Ǘ��ɗp������q�D���̈��q�ƌ��ݍ�p�͂Ȃ��D
�i�S�j�w�ʈ��q�@�����̏�ł�����ł��Ȃ����C���̈��q�ƌ��ݍ�p�������q�D
�@�Ⴆ�C�������ł����Ƃ������ƂȂ鐅��̕i������߂����������Ȃ�C������q�͕i��ƂȂ�܂��D�Ƃ��낪�i��Ƃ������q�͎{������Ƃ������q�ƌ��ݍ�p�����邱�Ƃ��킩���Ă��܂��D�����{�������_�Ƃ����ۂ̌���Ŏ��R�ɑI�ׂ�Ȃ�Ύ{�������������q�Ɋ܂߂����������܂��D�������C���Ƃ��Ύ����̕x�h�{����Ŏ{������R�ɑI�ׂȂ��C���邢�͐����̊W��C�c�A���̎����i����j�����R�ɑI�ׂȂ��Ȃ�C�{������͔_�Ǝ�����ł͐���ł��܂����C����ł͐���ł��Ȃ��W�����q�Ƃ������ƂɂȂ�܂��D����ɔN�ɂ���āC���邢�͎Y�n�ɂ���Ď��ʂ��قȂ�C�i��ƌ��ݍ�p���F�߂���Ȃ�C����͎����̏�ł�����ł��Ȃ��̂ŁC�w�ʈ��q�Ƃ������ƂɂȂ�܂��D
�@�����Ŗ��炩�ɂ��������q�Ɛ����m�ɂ�����C���̈��q�ƌ��ݍ�p�̂�����q�̂����C�����I�ɏd�v�Ȃ��̂��Ȃ������悭�l���܂��傤�D
�R�D�덷�̐���
�i�P�j���U���͂ƌ덷
�@��قǏq�ׂ����q�����ʂ�����̂���m�铝�v�I��@�����U���͂ł��D���U���͂ł͎���ʂ���ݍ�p�̑傫�����덷�ϓ��Ɣ�r����̂ŁC�덷���������ł���Ό��o�͂����܂�܂��D�ł͂ǂ̂悤�ɂ�����덷�����������ł���ł��傤���H�������C���̑O�Ɍ덷�̎�ނɂ��čl���Ȃ���Ȃ�܂���D
�@�e�����قȂ�f�[�^�𑊊֕��͂Ɖ�A���͂̂��ꂼ��ɂ��Ē������܂��傤�D���̂��߂Ɏ��O�ɂǂ������f�[�^�����邩��204���O�̃z���C�g�{�[�h�ɂ��鎆�ɋL�����āC1��8���i�j�ߌ�5���܂łɕ��C���i���Ă��������i�e�[�}�͑����ҏ����Ƃ��܂��j�D
�@�Ȃ������Ɖ^���̂悤�ɕЕ����w�肷��Ƃ��������������Ȃ��C���܂��Ă��܂��f�[�^�͂��̂悤�ȉ�͂ɂ͂ӂ��킵������܂���D���ʁC�s���{���̃f�[�^�̏ꍇ�C�k�C���Ⓦ���s�̂悤�ɖʐς�l���̋ɒ[�ɑ傫���f�[�^��������͖̂]�܂�������܂���D
�a�D����͑��֕��͂Ɖ�A���͂ɂ��Ċw�т܂��D
�@���֕��͂Ƃ͂Q�̕ϗʊԂ̊W�̋����𑊊W���Ƃ����l�����߂Ē��ׂ���@�ł��D��A���͂Ƃ͂Q�̕ϗʂ̊W���ǂ̂��炢���邩���ʓI�Ɍ��ς���C����ɂQ�̕ϗʂ̊Ԃ̊W�����鎮�ɕ\��������@�ł��D���ɂ͎U�z�}�i�Q�̕ϗʂ̂����C����������ɁC��������������ɂ��āC���҂̊W��}�������}�j�̃p�^�[��������������܂��D���͂���������C������������X��������W�������܂��D���̗�Ƃ��ẮC���E�e�n�_�ł̈�N�̍ō��C���ƍŒ�C���ɂ͂��̂悤�ȊW������ł��傤�D���͂���������C���͌���X���̂���W�������܂��D���̗�Ƃ��ẮC��N�Ԃ̐��V�̓����ƍ~���ʂ̊W���������܂��D���͂��Ƃ��̊ԂɊW���Ȃ����Ƃ������܂��D���̗�Ƃ��ẮC�k�ɂł̃I�[�����̐��Ɠ����w�Ŕ����ٓ��̐������邩������܂���i���Ԃ�W�͂Ȃ��Ƃ͎v���܂����������j�D
�P�D�ȏ�̂��C���C���̂R�̃p�^�[���ɓ��Ă͂܂�Q�̕ϗʂ��l���܂��傤�D
�Q�D�@���������͂��̃p�^�[���ɂ��Ă͂܂肻���ȃf�[�^�̑g�ݍ��킹�ɂ��āC���ցC��A���ꂼ��ɓ��Ă͂܂�20�g�ȏ�̃f�[�^���W�߁C�U�z�}�������܂��傤�D
�R�D�@�Q�D�ŏ������U�z�}�����āC�Q�̕ϗʂ̊W���ǂ̒��x�����̂����l���܂��傤�D���Ȃ킿���̐}�ł������͂��̕������ϐ��̊W�������Ƃ����܂��D�����̏W�߂��f�[�^���E�̃p�^�[���Ɣ�r���C�ǂ�ɋ߂������l���܂��傤�D
�@������12���̎q�i�̏d����1�`12�ԁj��3��ށi�`�C�a�C�b�j�̉a��^���鏈���ɂ��āC�t�B�b�V���[�̎O������K�p���Ă݂܂��傤�D���S������@�ł�12���Ƀ����_���ɂ`�C�a�C�b�����蓖�Ă܂��D�Ⴆ�Ή��̕\�̂悤�ɂȂ����Ƃ��܂��傤�D
�@���̂悤�ɋǏ��Ǘ����ꂽ�i�����ł͑̏d���Ȃ�ׂ������ɂȂ�悤�ɋǏ��Ǘ������j�u���b�N�����C�u���b�N���q�ȊO�̌n���덷�����R�덷�ɓ]�����邽�߂Ƀu���b�N���ł͖���ׂɔz�u������@�𗐉�@�Ƃ����C����@�ł̓t�B�b�V���[�̎O���������ׂĖ�������{�I�Ȏ����v��ł��D����@�ł͓z�u�Ɠ����悤�ɕ��U���͂ł��܂��D���Ȃ킿�v���̈���u���b�N���q�ƍl���C�����ōl������q�Ƃ̓z�u�ōl�@���邱�ƂɂȂ�܂��D�u���b�N���q�͐�����q��W�����q�ƌ��ݍ�p���Ȃ����Ƃ��O��ł��̂ŁC����@�̏ꍇ�C�J��Ԃ��̂Ȃ��z�u�ł����Ă����܂��܂���D
|
�ؔԍ�
|
�P
|
�Q
|
�R
|
�S
|
�T
|
�U
|
�V
|
�W
|
�X
|
�P�O
|
�P�P
|
�P�Q
|
|
����
|
5
|
3
|
1
|
12
|
7
|
2
|
9
|
8
|
4
|
6
|
11
|
10
|
|
����
|
�a
|
�`
|
�`
|
�b
|
�a
|
�`
|
�b
|
�a
|
�`
|
�a
|
�b
|
�b
|
�@���̂悤�Ȋ��S����ז@�œ���ꂽ�f�[�^�͈ꌳ�z�u�̕��U���͂ŏ����Ԃɍ�������̂�������ł��܂��D�i���S������@�ɂ��z�u���\�ł��j
�@�������C���O�Ɏq�̑̏d���킩���Ă���C����ɉa�̌��ʂ͑̏d�ɂ���ĈقȂ邱�Ƃ��킩���Ă���Ȃ�C�̏d�̋߂����̂��P�ɂ܂Ƃ߂āC���̃u���b�N���ł`�C�a�C�b���P�����蓖�Ă��������x�����サ�܂��D���Ȃ킿�̏d���Ƀu���b�N�P�i1�`3�j�C�u���b�N�Q�i4�`6�j�C�u���b�N�R�i7�`9�j�C�u���b�N�S�i10�`12�j�Ƃ��C�e�u���b�N���ł̓����_���ɂ`�C�a�C�b�����蓖�Ă܂��D
|
�u���b�N
|
�P
|
�Q
|
�R
|
�S
|
|
�ؔԍ�
|
�P
|
�Q
|
�R
|
�S
|
�T
|
�U
|
�V
|
�W
|
�X
|
�P�O
|
�P�P
|
�P�Q
|
|
����
|
3
|
2
|
1
|
2
|
1
|
3
|
1
|
2
|
3
|
3
|
1
|
2
|
|
����
|
�b
|
�a
|
�`
|
�a
|
�`
|
�b
|
�`
|
�a
|
�b
|
�b
|
�`
|
�a
|
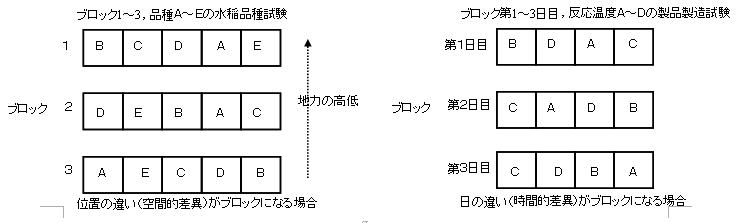
�@�Ƃ���ŗ���@�ɂ���Ζ��Ȃ��Ƃ������āC�ǂ�Ȍn���덷���u���b�N�Ԃ̍��ɂ��ď������邱�Ƃ��l���Ȃ��łƂɂ�������@���g���l�����܂����C����ł͌덷�𐧌䂷�邱�Ƃɂ͂Ȃ�܂���D��������Ƃ��ɂ͂ǂ̂悤�Ȍn���덷������̂����悭�l���C�u���b�N�����邱�Ƃɂ���Ă����Ƃ����ʓI�ɏ����ł���n���덷�ɑ��ė���@��K�p���܂��傤�D�ޏ�̒n�͂ނ�Ȃ�ǂ̕����Ƃǂ̕������ނ炪�傫���̂��C�ǂ̕������Ƃ���̒��͋ψ�ɋ߂���̃u���b�N�ƌ��Ȃ���̂��Ƃ������Ƃ��l���܂��傤�D
�@���̂Q�̐}�̂����C�E�͐���̕i���r�����̂悤�ɕޏ�̒n�͂ނ�i��ԓI�ȈႢ�j���u���b�N���q�Ƃ��ė���@�ɂ���ď�����������z�u�C���͍H��ł̐��������̂悤�ɓ��̈Ⴂ�i���ԓI�ȈႢ�j���u���b�N���q�Ƃ��ė���@�ɂ���ď�����������z�u�ł��D
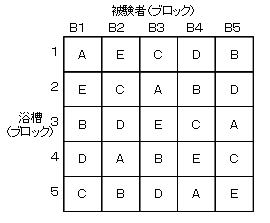
�@�l�����ׂ��u���b�N���q���Q�������ꍇ�̓��e�����i�@�ɂ���ău���b�N���q�𐧌���q�̊e�����ɋϓ��Ɋ��蓖�Ă邱�Ƃ��ł��܂��D���e�����i�@�̕��U���͂̓G�N�Z���̕��̓c�[���ł͂ł��܂���D�lj��̃v���O��������ɓ���邩�C��荂�x�ȓ��v��̓\�t�g�Ń��e�����i�@�̕��U���͂����邱�ƂɂȂ�܂��D
�@�Ⴆ�C���̗�ł͂T��ނ̓����܁i�`�`�d�j�̌��ʃe�X�g���T�l�̔팱�ҁi�a�P�`�a�T�j�łT��ނ̗����i�P�`�T�j�ɂ��čs�������̂ł��D��������ƂT��ނ̓����܂͂��ꂼ��e�팱�ҁC�e�����ɂP�����蓖�Ă���̂Ŕ팱�҂◁���̍����u���b�N�ԍ��Ƃ��ď����ł���ƍl�����܂��D����Ƀu���b�N���ł͖���ׂɔz�u���邱�ƂŁC���̑��̖��m�̌n���덷�����R�덷�ɓ]���ł��܂��D
�@�ȏ�̂��Ƃ���n���덷�Ɩ�����E�Ǐ��Ǘ��ɂ��Ă܂Ƃ߂�ƈȉ��̂R�ɂȂ�܂��D
�`�@�n���덷�̌��������ׂĔc�����C�������邱�Ƃ͕s�\�Ȃ̂ŁC������͂ǂ�ȂƂ��ł����Ȃ炸���Ȃ���Ȃ�Ȃ��D
�a�@�n���덷�̌����������Ă���Ȃ�Ǐ��Ǘ��ł��Ȃ�̒��x�������邱�Ƃ��ł���D�������C�����̌n���덷�̌���������Ƃ��͂��̂���������덷�̑傫���Ȃ���̂𗐉�@�ł��邢�͂Q�����e�����i�@�ŏ�������D
�b�@�a�̋Ǐ��Ǘ��ŏ������Ȃ��n���덷�͖�����ŋ��R�덷�ɓ]������D